
What’s the Difference Between Logistic Regression and Decision Trees?
When you’re starting out in data science, choosing the “right” model can feel overwhelming. It is known that machine learning depends heavily on classification methods. Specifically, logistic regression and decision trees are two of the most common supervised learning algorithms used for classification.
What Are Different Types of Classification?
- Binary Classification: two possible outcomes
- Multiclass Classification: one correct among many
- Multilabel Classification: independent labels (sorting into differerent possible categories)
- Imbalanced Classification: skewed class distribution
- Ordinal Classification: ordered labels
- Hierachical Classification: parent-child label structure
In this article, these two methods, logistic regression and decision tree use primarily binary and multiclass. Both of these are unsupervised models for classificaition and regression tasks but logistic is better for linear, predictable, good for bianry outcomes and probabilities. Decision trees are non-linear and handle interactions, and support rule-based multiclass splits.
🤔 What Is Logistic Regression?
Despite the name, logistic regression is used for classification, not regression. Specifically, binary classification (e.g., predicting yes/no, 0/1, pass/fail).
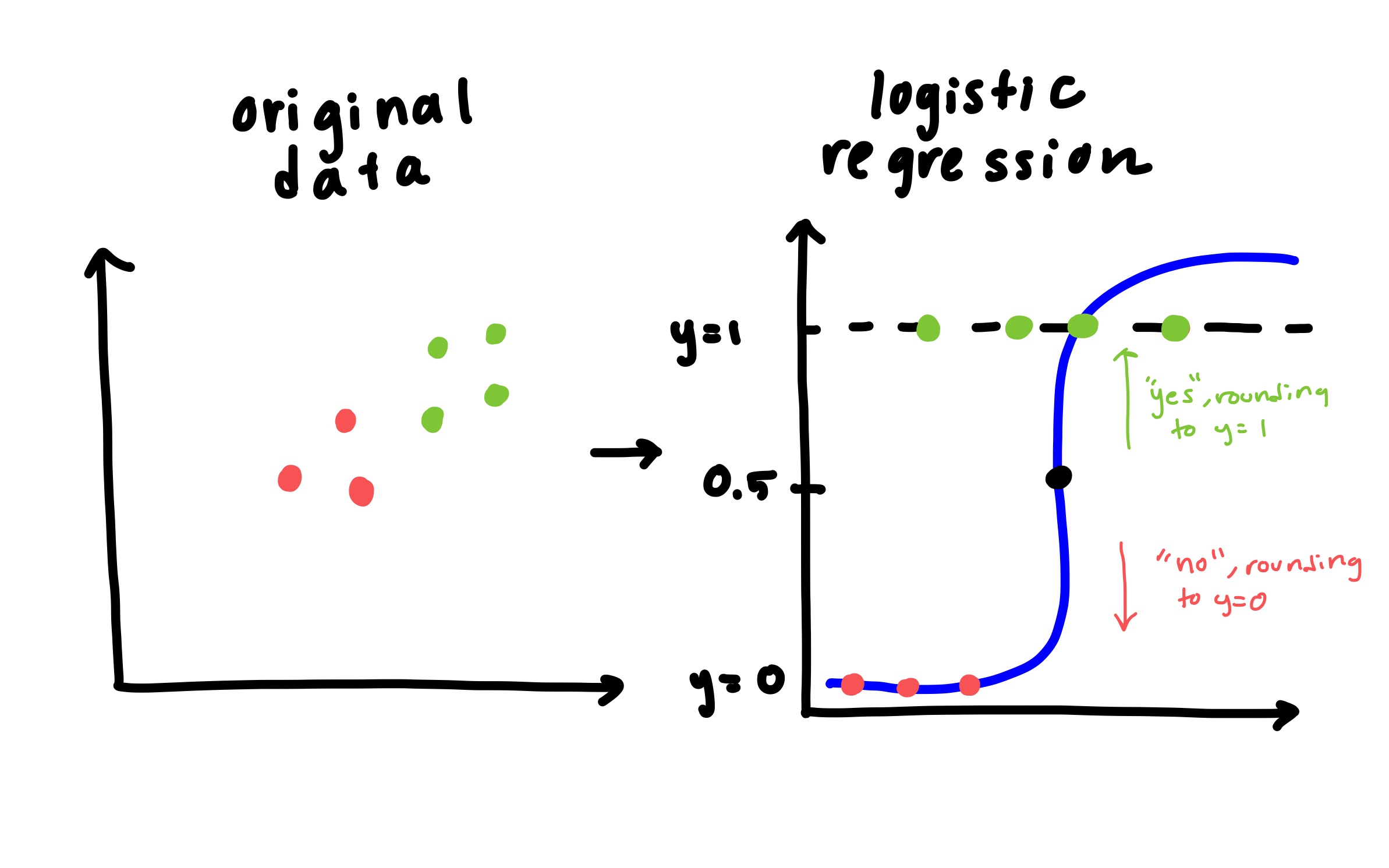
It estimates the probability that a given input belongs to a class using a linear combination of input features passed through a sigmoid function:
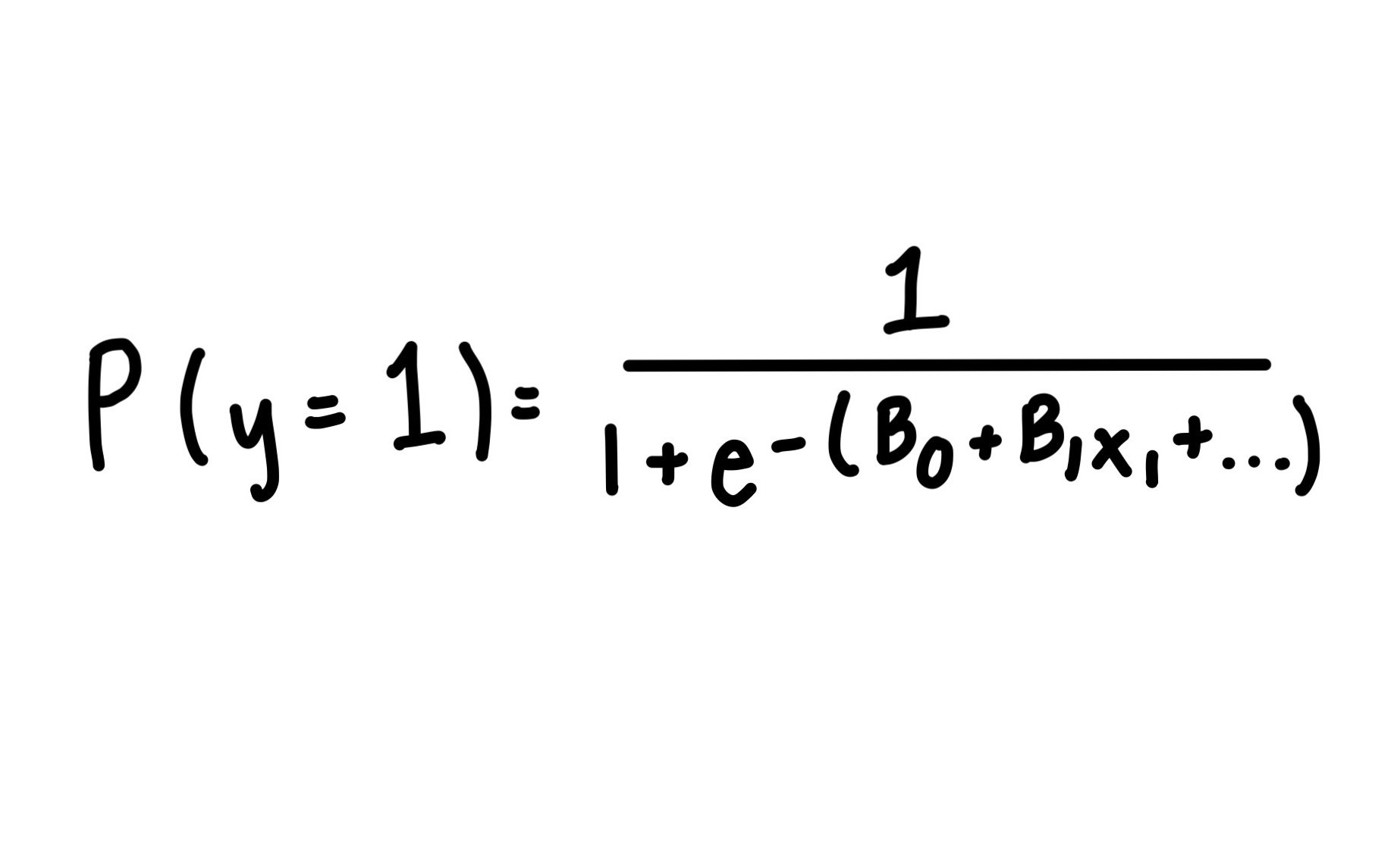
Sigmoid function used in logistic regression.
Sigmoid function used in logistic regression.
For examples, logistic regression in this case can map a point to 0 or 1, but it can also be 0.75 or something in between. If something is above 0.50 it’s considered a “yes” or true and if it’s below 0.50, it gets classified as a “no” or false. You set these conditions when making the model of what is “yes” or “no”.
Logistic regression works best when:
- The relationship between features and the log-odds of the target is linear
- Your data is relatively clean and not too complex
- Interpretability matters (you want to understand feature impact)
🟢 Pros: Fast, interpretable, low variance
🔴 Cons: Assumes linearity, struggles with complex patterns
Python Code Example: 🧪 Logistic Regression Example (Binary Classification)
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
#load binary classification dataset (malignant vs. benign)
X, y = load_breast_cancer(return_X_y=True)
# split data into train/test so you can train the model and then see if it worked after
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
#this is where you create and fit logistic regression model
model = LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
#now time to predict and evaluate
y_pred = model.predict(X_test)
print("Binary Logistic Regression Results:\n", classification_report(y_test, y_pred))
📌 Notes:
- This uses the
load_breast_cancer()dataset fromsklearn.datasets, which is a binary classification task: predicting whether a tumor is malignant or benign.
🌳 What Is a Decision Tree?
A decision tree splits the data into branches based on feature values, like a flowchart:
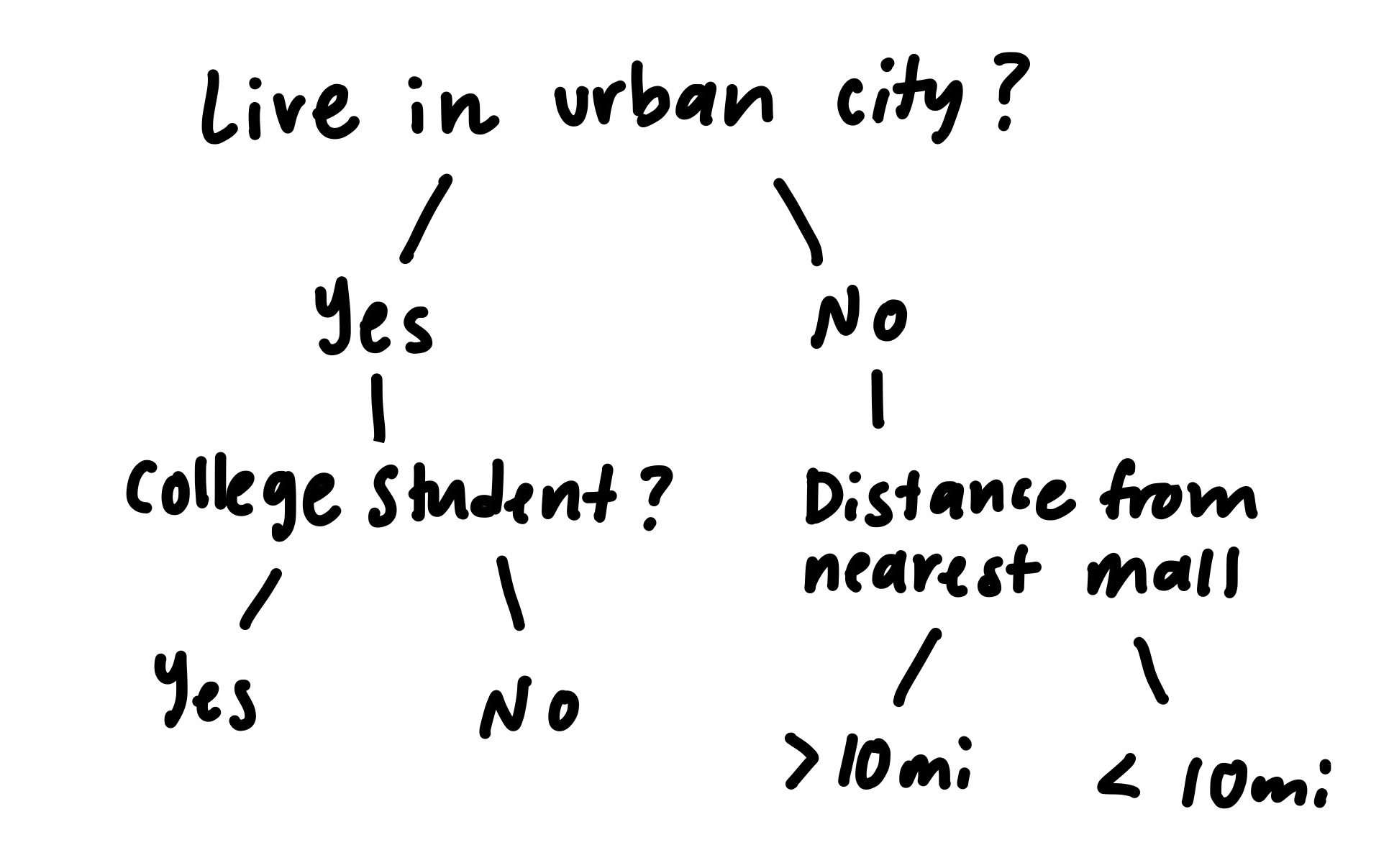
Example of a basic decision tree splitting on features.
It handles both classification and regression tasks and works well with non-linear relationships. It keeps splitting the data to minimize “impurity” using metrics like Gini or entropy (for classification).
Decision trees work best when:
- Your data has non-linear relationships or lots of interactions
- You want rules-based interpretations
- You’re okay with lower stability (small changes in data can change the tree)
🟢 Pros: Handles complex data, interpretable rules, no need to scale data
🔴 Cons: Prone to overfitting, not great with sparse data unless pruned or boosted
Python code example: 🌳 Decision Tree Classification Example (Multiclass)
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
#loading dataset
X, y = load_iris(return_X_y=True)
#splitting into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
#fit decision tree model
tree = DecisionTreeClassifier(max_depth=3, random_state=42)
tree.fit(X_train, y_train)
#and finally predict and evaluate
y_pred = tree.predict(X_test)
print("Decision Tree Results:\n", classification_report(y_test, y_pred))
🔍 Side-by-Side Comparison
| Feature | Logistic Regression | Decision Tree |
|---|---|---|
| Type | Linear Model | Non-linear Model |
| Use Case | Binary classification | Classification or regression |
| Interpretability | Coefficients show feature impact | Tree structure shows decisions |
| Handles Non-Linearity | ❌ Needs transformations | ✅ Naturally handles it |
| Risk of Overfitting | Low | High (if unpruned) |
| Scales Required? | Yes | No |
💡 Real-Life Example: Predicting SNAP Participation
Let’s say you’re building a model to predict if a household will apply for SNAP benefits based on income, household size, disability status, and employment.
- Logistic regression helps you see how each feature changes the odds of SNAP participation. It’s ideal if your stakeholders want to interpret model coefficients or need a quick baseline model.
- A decision tree can capture interactions — for instance, that households with low income and a disability are more likely to apply. It also makes it easier to explain logic to non-technical audiences.
✅ When to Use What?
Choose logistic regression when you want:
- A simple and interpretable model
- To avoid overfitting
- To estimate probabilities directly
Choose decision trees when you want:
- A model that captures non-linear patterns
- Clear “if-then” rules
- To prepare for ensemble methods like Random Forest or XGBoost
🧠 Final Takeaway
Both models are powerful in the right context. If your data is clean and linear, go with logistic regression. If it’s messy, complex, or you want to capture rule-based logic, try a decision tree.
Often, the best practice is to start simple and iterate.